
”「共起」が今後の検索に及ぼす変革で”サンフランシスコで開催されるSemtechBiz2013の招待状の件について軽く触れましたが、今日は改めてセマンティックSEOに関する概念を紹介します。
SemtechBiz2013のカンファレンスの主な内容は、fantastic list of key takeaways from the conferenceyよりスクラッチが確認できるようですので是非チェックしてみてください。今年も、エンティティやスキーマに関する話しや検索技術にどう活用していくか、実装ベースの方向性などについてのプレゼンテーションもあったようですが、現在GoogleやSEOに関連する分野については、ページや文章の意味理解という側面で大きな転換期にきているようです。どう変化していくのか、またどういった戦略・戦術を今後とるべきか、今後検討すべき課題点を明確にすべくブレークダウンしてみました。
そもそもSEOという言葉自体定義が曖昧で、日本でSEOといってきちんとした定義を答えられる人は少ないのかもしれませんが、私なりの定義は、
“「QWの意図についてマーケティングし、狙いたいゾーンのセグメント意図に最適なサイト、ページ(コンテンツ)にすべくオプティマイズ(最適化)する」
では、セマンティックSEOとはどう適宜されるでしょうか?まず結論から
“「セマンティックサーチは、意味ある結果を返すことを目的とした検索または質問である。問いかけに対して抽出されるページや対象物は、QW(クエリーワード)を含んでいる必要はなく、検索者は、ズバリ探す対象を示すキーワードで検索するとは限らない。
皆さんこれどういうことかわかりますか?
セマンティックWEBについては、その発想がささやかれてから7,8年以上経つとは思いますが単語の並びだけをインデックスしてひっかける検索ではなく、フレーズや、そのフレーズの意味を解釈するために語彙ライブラリを構築して検索技術に活かそうというものです。
数年前からエンティティベースのSEOなどと囁かれていますが、SemTecBizは、2006年当時からセマンティックなWebを広め、研究する人達が集まっているフォーラムだったと思います。当時、ロスに行けない場合は、Webinarに申し込むと同時中継でセミナーに参加できましたが、今では大分大きくなったようですね。
2008年のフォーラムはWebinarより私も参加したことがあるのですが、当時Cogito社のエンジニアがセマンティック技術を検索にどう活かすかというプレゼンテーションを懐かしく思い出しました。
こちらのフォーラムの様子は過去のものですが、非常に基礎から分かり易い内容となっていますのでまた別の機会に当時の映像を踏まえてご紹介させていただきます。
エンティティベースの検索だとか、スキーマによるマークアップなど最近良く耳にするようになってきましたが、このエンティティというのは、リレーショナルデータベースのエンティティのようにスキーマとしてライブラリー化されたようなものだと想像してください。
このエンティティに例えば、ホスト単位、ページ単位、文節単位、ひょっとすると音楽ソースや映像ソースまで関連付けることによって、このエンティティは言うなれば、“概念”としてあらゆるものを引っ張りだす際の便利な書庫のようなものになるという発想です。
“Entity-based SEO”や”Search Entity Optimizetion“などと言われていますが、このEntitiyを介したサーチへサーチエンジンがシフトする中で、この概念は重要な要素となりそうです。
今後SEOはいずれセマンティックSEO、エンティティベースのオプティマイゼーションに適応すべき時期到来するかもしれません。セマンティックWeb技術、エンティティベースの検索技術についての詳細は、また別の機会に解りやすく扱おうと思いますので、その際は参考にしてみてください。
Justin氏のサイトで分かりやすく紐解かれていましたので詳細を知りたい方はこちらをどうぞ。
先のパラグラフでもRDBMSやER設計などを例にちらっとさわりましたが、そもそもエンティティと言われても文系の人にとっては今ひとつ捉えにくい概念かもしれませんので、Justin氏のサイトの図表などをお借りして詳しく説明してみます。
旧来のページランクが、HITS理論をベースとしたアンカーリンク投票によりオーソリティページやホストスコアリングを行うものだったとすると、エンティティベースというのは、様々なオーソリサイトやFreeBaseなデータ・ソースから共通に扱っている要素をエンティティとして関連付けるというイメージです。ですので、ページに含まれるキーワードやキーフレーズなどフレーズインデクシングによる候補抽出とはまったく違った概念のクエリー応答となります。
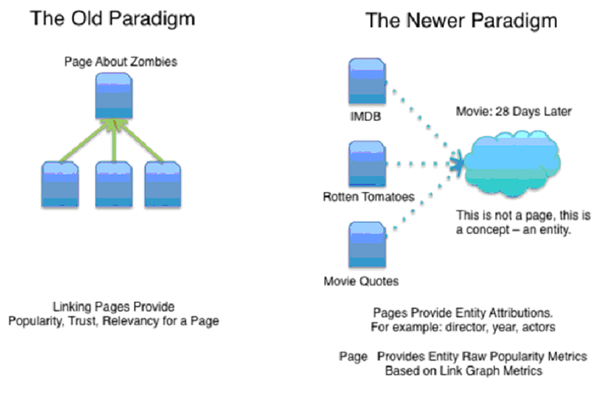
図のように、ページランクに活用されているハブ・オーソリ理論的に例えると、ゾンビに関するページに複数のページからリンクがある場合、図のPage about zombiesに関する信頼性やレレバンシー、著名度などがアトリビュートされ、ページランクへ活かされていると言えますね。逆にエンティティベースになると「図中ではニューパラダイム」と言及していますが、例えば映画に関する例を取ってみると次のようなイメージとなります。ページ自体は、リンクグラフによる著名度が十分高いページという前提です。
| スキーマ | エンティティ | 概念・コンセプト |
|---|---|---|
| iMDB (インターネットムービーデータベース) |
映画"28日後"の基礎データ | 「映画28日後」に含まれる要素 →「映画28日後」に関連するすべての情報 キャスト・監督、脚本家、DVC、上映スケジュール、ユーザー評価、評論、ちなんだエピソードなど →この場合公式サイトだったり、DVD販売サイトだったり、αなブロガーだったり... |
| RottenTomatoes 映画レビューサイト |
映画評論化による映画28日後のレビュー・評価点 | |
| 映画の台詞を 引用しているページ |
映画中のセリフ |
これまでの検索対策の流れですと、28日後という映画に関する文章であると示すためには、形態素解析を用いながらタイトルタグやメタやh1やbody内に該当するキーフレーズやキーワードを入れることが一般的であったと思いますが、エンティティベースの検索の場合は具体的にページに映画タイトルを示すようなキーワードやキーフレーズなどが存在しなくても、図上のアトリビュートバリューテーブルのようにマッピングされたインデックスより、最適なページを抽出することができるようなイメージです。 エンティティーベースの検索に関するSERPSイメージは、現在のナレッジグラフに近いイメージになるかもしれません。
現在のナレッジグラフを見ていると、エンティティにマッピングされた対象を認識できる有益なライブラリーをWalframのようにきちんと文脈ある内容で整理してSERPS上に表示されていることに気づくと思います。
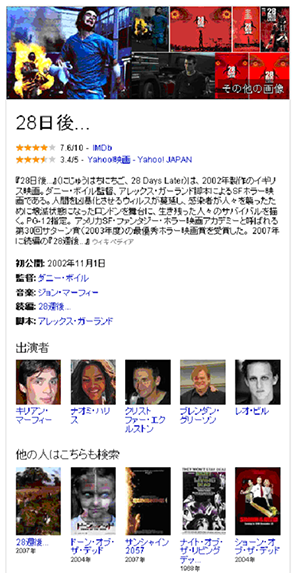 日本語で、"28日後"と検索すると映画の概要トiMDB、Yahoo!映画などのレビュー評価、各種バイオグラフィーや出演者、監督情報等が表示されます。
日本語で、"28日後"と検索すると映画の概要トiMDB、Yahoo!映画などのレビュー評価、各種バイオグラフィーや出演者、監督情報等が表示されます。
また、左の結果の中から、気になる情報をクリックすると、関連するスコアリングの高いページ順にランキング表示が切り替わります。
↓ナオミ・ハリスをクリックすると上段に関連するキャストや俳優と左下SERPS上にナオミ・ハリス関連するWikiや映画公式サイト、最新出演映画のYouTubeトレイラー映像などQDF,QDDアルゴリズムにしたがって表示されているのがわかります。
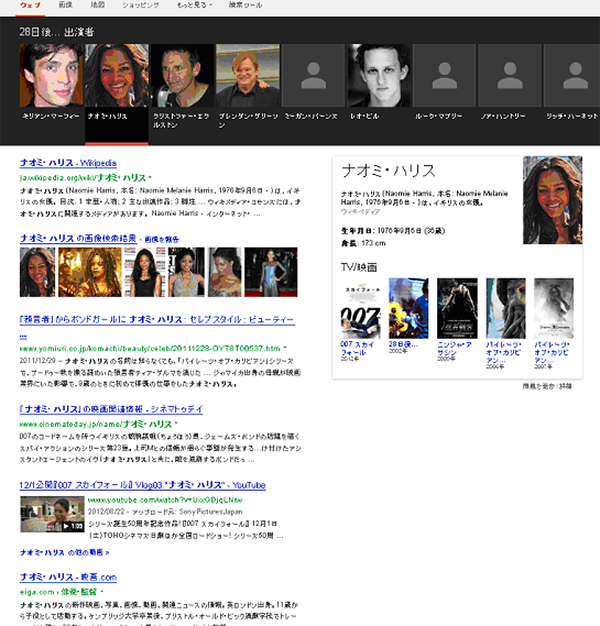
実はナオミ・ハリスの最新出演作のトレイラーを探していたとした場合、「ナオミ・ハリス 最新出演作」とQWを入力しなくても、彼女が出演していた映画"28日後"と検索してこの結果にたどり着くことができるのです。現在はまだ発展過程だと想定すると、数年後には、クリックデータなど統計的な要素も蓄積されてゆき、「28日後」と入力したさいのSERPSを構成するQDF,QDDの概念はガラっと変わってくるかもしれませんね。
なぜなら、検索ワード意図の解釈にこのエンティティベースの構造化データが活用されるようになると、より自然な意図するリザルトを返せるようになることは容易に想像ができるからです。少なくとも、今後1,2年の間にAndoridOSとしてモバイル上からの位置情報、パーソナライズされた動態情報などが加味されることも忘れてはいけません。これが何を意味するか想像してみると、シチュエーション、オケージョンにより、サーチリザルトが変化するということでしょうか?
現時点の答えは、半分「YES」
いくつかの深い記事やフォーラムビデオを見てみましたが、どうやらキーワードはまだ当面の間は、ユーザーの検索意図を解釈するトリガーとして有効な手段であることに変わりはないようです。
エンティティベースの検索や現在のナレッジグラフについては、あくまでもユーザーの検索意図を予測する域での設計となっているためだからです。先にキャプチャーしたナレッジグラフのUIを実際に見てもらえれば分かると思いますが、想定されるアトリビュート要素を綺麗に整理して、1つの結果ページ上から複数のSERPSを展開できることに気づいたでしょうか?
ナレッジグラフ導入の前は、1ページ目10個の結果にお目当てのものがない場合は、2ページ目へ移るか、検索ワードを変えて検索しなおすことが一般的であったと思いますが、セマンティックSEO(エンティティーベースのSEO)では1つのキーワードから、全然別の意図する結果に辿るつくことができるのです。
”セレンディピティ(Serendipity)”などと呼ばれるように「意図しない流れのなからたまたま発見する」という比喩もできますが、エンティティベースの検索では、薄ら覚えのキーフレーズからお目当てのものを探すことができる、またはそれを切っ掛けとして別の要素が目的なるといった探索プロセス自体を楽しめる(ナレッジを広げられる楽しさ)、判断、比較出来る要素が増えるという点でオーガニックマーケティングにおけるインテンション分析(ニーズ・ウォンツ)の奥深さは今までとは全く違ったものになることは明らかです。
現時点でも、前回触れたように、一部こうした技術が裏側で採用されたのではないかという事象も確認されているのも事実です。
キーワードによるマッチング検索が確固たるものであるかどうかは分からなくなるようないくつかの事例も確認されてきているのも事実です。GoogleTalkなどが動向も今後注視すべきですね。また、前回の記事にで紹介した、ページ内に検索キーワードが存在せず、バックリンク構造体にもアンカーテキストなどが存在しない等、旧来のSEO知識では解析不能な事例が出てきていることも事実です。
今後の動向に留意ですね。
スパム要素は見ない事としてざっくりGoogleのランキング要素をあげてみると下記3つのイメージです。
1.サイトやページの著名度、人気投票、信頼度シグナル
→信頼されるサイト、関連あるサイトからの外部リンク、引用リンク、ソーシャルシグナル(シェアやいいね)
2.QWに対する関連性・妥当性シグナル
→ページ自体の妥当性、意味があるページ。例)phrase-based indexing
3.SERPS上に直接表示される要素
→タイトルタグキーワード、URL、METAデータなど
この要素に構造化データによる意味づけや検索意図解釈がどういった影響を及ぼすかと予想すると、個人的見解としては、QW意図に対する結果の妥当性・関連性に関する部分に影響があるのではないかと考えています。下は、Googleによるパテントの一部Phrase-based indexingで使用されている図ですが、これはまさにキーワード・フレーズに関するエンティティベースの解析といっていいと思います。
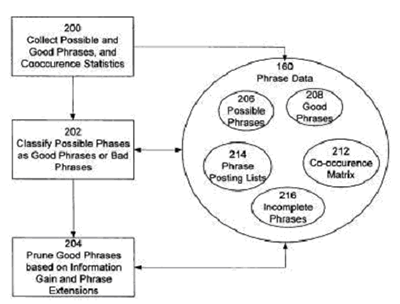
右の160から216までがさまざまなフレーズやキーワードのエンティティライブラリとします。GoodPhraseやIncompletPraseや有るキーワードとよく使われる関連フレーズリストなどがインデックスされています。(Phrase-based indexing)
”右200”の処理でページ上で使われているキーワードやフレーズについて右の(Phrase-based indexing)に照らし合わせてピックアップして行きく。
”右202”の処理で良いフレーズやありえない組み合わせのフレーズなど分類
”右204”の処理で意味のあるレレバントなフレーズを認識しそのページ価値を推し量る。
こうした有るテーマに関するキーワードや関連フレーズの出現パターンなどがPrase-base indexingという技術によりエンティティ化されているということです。検索する上でまったく関係ないキーワードを拾って表示されたり、パンダアルゴリズムで、内容の無い、意味不明な文章に巧みにキーワードを入れてもバレるのも分かりますね。
このようにPharse-based indexingは、主にパンダに関するものと考えていますが、Thin Affililateコンテンツやファームコンテンツ、Key Word Staffingなどの解析に使われているといえますね。
GoogleやYahoo!.comやBingなどが提唱している構造化データの枠組みとしてschema.orgがありますが、これは、特にデータベース型サイトでは、schema.orgなどの仕様に基づいてマークアップすることで、インテンションがあいまいなQWやロングテールワード、指名ワードなどで威力を発揮するかもしれません。まだschema.orgは実際の検索結果に反映するまでに至っていないようですが、DB型サイトはシステム上大手でしたらダイナミックに対応可能な面もあるため、やっているところとやっていないところとで、どこかのタイミングで勝ち組、負け組みが明確になるかもしれません。
Rel=”author”についても当初はまだ先かなぁという感じでしたが、もう当たり前のようにSERPS上高順位に表示されるようになっているのに皆さんお気づきの方も多いと思います。
翻訳はしませんが、セマンティックなコンセプトとそれをどう検索に活かそうとしているか1時間以上にわたり分かりやすく解説されています。こちらのエッセンスはまた次の機会になるべく解りやすく取り扱う予定ですので、その回で改めてご確認ください。本日の記事では、ビデオのみembedさせていただきます。
エンティティが検索技術と融合することで、以下にパワフルな検索ができるようになるのか、エンティティの概念をはじめ、構造化データをビルドしてゆくことの重要性と価値について非常に解りやすく説明されています。
2011年1月にGoogle Andrew Hoge氏によるGoogle TechTalsによるプレゼンテーション模様です。
このビデオの中で当時の段階で下記4つの課題についてGoogle社がすでに解を持っていたのが分かります。
1.Can we understand the world out side the web?
→YES!Freebase and Extraction2.Can we better understand queries?
→Yes! Query Parsing and Qeury Answering3.Can we better understand content?
→Yes! Sentiment Analysis4.Can we make Google do the work for you?
→Google Squared
※Google SquaredはWalframの対抗馬としてGoogleが開始したサービスですが、今ではその役目を終えて開発は終了しています。
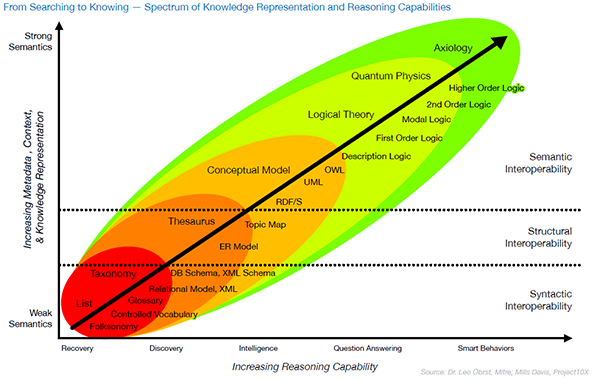
結構前の資料ですが、フォークソノミーからはじまりオントロジーから物事を把握できるようなコンピューティング技術発展までのロードマップが示されています。
ERモデリングと言った初期のモデリングからRDF/s(Metaweb:schema.orgが今持ち上げられているようですが)、UML,OWLといった高度なモデリングを経て
といった流れは、2013年現在の流れを見ると着実に具現化されているんだなぁと考えさせられました。
今回は、長文な投稿となりましたが、ねずみ小僧的には、また新たな対策ストーリーが練られるので楽しみな限りです。それではまた次回!
 PaydayLoanAlgolithm3.0が正式ローンチ...
PaydayLoanAlgolithm3.0が正式ローンチ...
 先週末ロールアウトしたアルゴリズムまとめ:Panda4.0とPayDayLoanアルゴリズムについて...
先週末ロールアウトしたアルゴリズムまとめ:Panda4.0とPayDayLoanアルゴリズムについて...
 Google検索結果画面仕様変更はモバイルを意識した対策か!?...
Google検索結果画面仕様変更はモバイルを意識した対策か!?...
 クエリーワードベースの検索の大きな課題とグーグルセマンティック検索へのアプローチ方法について...
クエリーワードベースの検索の大きな課題とグーグルセマンティック検索へのアプローチ方法について...
 腐敗するゲストブログを活用したリンクビルディング。被害に会わないためのリスク管理体制が必要に!?...
腐敗するゲストブログを活用したリンクビルディング。被害に会わないためのリスク管理体制が必要に!?...
 2013年06月27日
2013年06月27日