
searchenginland:久々にEric氏の記事を目にしましたが、今日はGoogle Semantic Searchという本を題材に今後10年程度かけてセマンティックな文脈で検索がどう変わるのか分かり易く説明されていましたので紹介します。当サイトでも「MBAコースにGoogle Semantic Searchがカリキュラムとして登場!?」で当該本は紹介しましたが、恥ずかしながら時間の都合で私はまだ読めていません。一般論として現在垣間見ることができるセマンティックな検索については、荒っぽく言うとハミングバードなどによる検索意図の機械的な解釈精度の向上(対話型検索)やナレッジグラフに代表される膨大な構造化データ(執筆者や企業などのソーシャルプロファイルも含む)を意味付けしインデックスに生かすという2本立てという形で個人的には理解しておりますが、数年先を見越してこれからどうのように考えるといいか、そのヒントがEric氏の記事から多少なりとも見つかるかもしれません。
皆さんもご存知のとおりグーグルは、リンクベースのアルゴリズムを採用することで、検索精度をより良いものにしてきたそうですが、依然として、「そのページが何について書かれているものか」という判断には、Webページ上にコーディングされている単語やフレーズに頼っているのが実態です。現在のこうした検索の仕組みにおける課題についてEric氏の記事では大きく2つ上げています。
この事実は、「一般の人にとってはちょっと敷居いが高いのではないか?」ということなのです。例えば、WindowScreen(網戸)と短いフレーズで検索すると良い結果が得られると想像できますが、「2階建ての戸建にふさわしい新しい網戸がほしい」と検索しても「WindowScreen」と検索するよりもふさわしい結果がでるとは限らないとうことだそうです。本来であれば、長い文章での検索はより自分がほしいものを適確に述べたものだと言えるのですが、現在の検索の仕組みではこうはならないといういう事が一つの課題であると述べられています。
例えば、Jaguarという言葉は、ネコ科の動物の「ジャガー」や車の「ジャガー」、マックOSの「ジャガー」からギターの「ジャガー」、はてはフットボールチームまで多くの物や事を意味します。ですから、検索者はこうした複数の意味を持つキーワードに関連する事柄を正確に検索するには、検索結果を見て、ちょっとした工夫をしなければならないという事です。
Ericさんの記事からちょっと離れますが、セマンティックウェブ技術については、上にあったJaguarという単語について、どういったJaguarがあるのかまずは構造化データベースに格納し、その上で文脈を返して(例えば、時と場合によってなど)その「Jaguar」意味するところが変わってくるという代物だとかなり粗々ですが理解できると思います。Eric氏の記事では、例として「show me pictures of empire state buildig」と検索した後、「How tall is it」と検索すると「1,454'(443m)」と検索結果が出るような事例があげられていますが、こうした結果を導くために、グーグルは、まずエンパイヤ―ステートビルディングには高さという特性(属性)を有しており、更に、検索者が直近の検索でエンパイヤ―ステートビルの画像を検索したということを理解している必要があるという感じです。
記事ではまだこうした対話型なコンテキスチュアルな検索はAndroidなどの音声検索を中心に徐々に実用化されている段階であり、PCでいう検索窓に検索キーワードを入力するケースは従来のアルゴリズムがもっぱら主流だと述べられていますが、このような人口知能的な検索体験が10年程度で実現されるとしたら今までの検索と比較してより検索という問い合わせ行為がユーザーオリエントなインターフェースになると予想できそうです。
Eric氏の記事では、10年スパンで考えると、Google Semantic Searchで述べられているセマンティックな文脈解釈技術がかなりの精度で実用化されるのではないかということです。今スグという訳ではないのかもしれませんが、パソコンの出荷台数が激減し、スマホやファブレット、タブレットが主流なクライアント端末になると仮定すると実はもっとこうした流れは早まるかもしれませんね。なぜならば、そうした端末からの問い合わせデータが増えることで、文脈解釈をするためのビックデータがより早くグーグルに蓄積されることが予想できるからです。
以下は、Dvivid Amerland氏によるインフォグラフィックです。
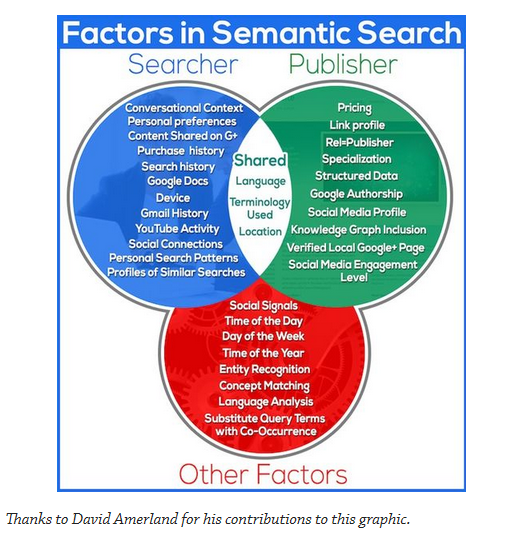
セマンティック・ウェブについては、2006年ぐらいにcogto社のwebinarなどで「随分前になるほどなぁ」と拝見させていただいたことがありますが、当時の記憶を呼び起こすと、Jaguarといういろいろな意味を持ちうる単語を文脈を踏まえ認識するためにさまざまなエンティティ(ライブラリ)を持たせ、時間や場面、Jaguarと連想したその人の行動などからどんなJaguarを意図しているかこうやって分析・解釈する的な内容だっと思います。
では検索ではどう置き換わるか?
上の図のまとめが非常に分かり易いですね。「検索者」、「コンテンツ」、「その他の要素」の3つの要素がセマンティックなコンテキストでより明快に処理できるようになると考えると、将来に向けて現在投資している内容を無駄にしないためにどういった観点で取り組むと良いかヒントが見えてくるかもしれません。
(1)検索者
対話型なコンテキスト重視の検索をするようになる。その人がいる場所や直近検索した文脈に沿ってドリルダウンするような検索をするようになる。
(例:はじめはビックなワードで検索し、次に問い合わせ型の検索フレーズで検索するなど)当然、文脈から適切な意図を解釈した検索エンジンはよりニッチなページかもしれないが、信頼でき、その人のニーズにとって有益であろうページを上位に提示するというイメージ)(2)コンテンツ発行者
信頼性・権威度をどう証明するか?、構造化し、しっかりページの内容を認識してもらう、オンライン上のレピュテーションなどもアピールする。
(例:ニッチであったり、新参ものであっても、しっかりした顧客ファンを有しており、その活動がソーシャルグラフやエンティティを通してきちんと構造化されている)(3)その他の要素
ソーシャルシグナル(Googleの場合は、Google+になりそう)、日時、年次という時間軸の概念、構造化データを文脈で解釈できるエンジン、自然言語解析などによる検索ワードの置き換え技術。。等
(例:(1)検索者の検索行為と(2)コンテンツ発行者の間を文脈や時と場合に即したフィルターを通して適切に結びつける)
といった形でイメージしてみました。こうした要素をベースに
volume コンテンツのボリューム(量ではなくその中身)
velocity (コンテンツの速さ:これは多分モバイルでの用途を重視?)
vraiety (多様性)
veracity (正確性と信頼性)
といった事柄をはかりにかけられて検索結果に登場できるようになるという感じでしょうか。
私も時間をみて是非GoogleSemanticSearchを読んでみたいと思います。ひょっとするとGoogleNowやナレッジグラフのようなインターフェースにまとめて表示されることとなるかもしれませんが、5年後、10年後の検索の世界がどうなるか今から楽しみでもあります。
 PaydayLoanAlgolithm3.0が正式ローンチ...
PaydayLoanAlgolithm3.0が正式ローンチ...
 先週末ロールアウトしたアルゴリズムまとめ:Panda4.0とPayDayLoanアルゴリズムについて...
先週末ロールアウトしたアルゴリズムまとめ:Panda4.0とPayDayLoanアルゴリズムについて...
 Google検索結果画面仕様変更はモバイルを意識した対策か!?...
クエリーワードベースの検索の大きな課題とグーグルセマンティック検索へのアプローチ方法について...
Google検索結果画面仕様変更はモバイルを意識した対策か!?...
クエリーワードベースの検索の大きな課題とグーグルセマンティック検索へのアプローチ方法について...
 腐敗するゲストブログを活用したリンクビルディング。被害に会わないためのリスク管理体制が必要に!?...
腐敗するゲストブログを活用したリンクビルディング。被害に会わないためのリスク管理体制が必要に!?...
 2014年03月02日
2014年03月02日