
先日Googleのマット・カッツさんがペンギンアップデート2.1を導入したとの記事を書きました。週末の間、ウォッチしているワード群での順位動向をチェックしていましたが、これといって特徴だった動きがありませんでしたので、2.0から2.1へのリビジョンアップということもあり、データリフレッシュ程度の変更だったのかと一先ず初動の動きを方向付けようかなと考えていました。
ところが、「SEACH ENGINE ROUNDTABELE」のエグゼクティブエディターであるバリー氏が、先ほど「Google Penguin 2.1 Was A Big Hit」というタイトルで記事をアップしました。

SEOをやっている方はすでにお気づきの方もいらっしゃるかと思いますが、ビッグキーワード「キャッシング」というクエリワードで上位表示していた比較サイトが圏外に下落しました。
サイトのコンテンツ内容から判断するとおそらく外部施策が要因と考えられるため、第三者でも確認できるレベルでチェックしてみました。

SEJより:「SEOの順位をできる限りコントロールできるようになったら..」というのは誰しも一度は考えた事があるのではないでしょうか?rel=authorを上手に活用することで、少なからずSEOについてごく一部ですが、「自分次第」でなんとかできそうだと勇気づけられる記事です。rel=authorをきちんと活用することで、さまざまなメリットがあるんですという内容ですが、そのメリットを5つの視点で私の考察も若干加味させていただきながら整理しつつ紹介させて頂きます。

本日10月5日未明、Googleのマット・カッツさんがペンギンアップデート2.1を導入したとツイートしました。その変更による影響は~1%とのことです。より詳細な情報はまだ入っていません。
アメリカと日本のSEO順位変動のウェザーレポートツールの紹介と最後に経営層とねずみ小僧の想定やりとりをシミュレートしてみました。
続報がありましたら、別記事にてご紹介させていただきます。

![]() 今日はマドリッドのクリスチャンからの質問。「内部リンクも本当は"rel=nofollow"とした方が理にかなっているのではないでしょうか?例えばログインセッション時のページへのリンクなどはその方がいいように思います。内部リンクrel=nofollowとするのとしないのとで違いはありますか?」
今日はマドリッドのクリスチャンからの質問。「内部リンクも本当は"rel=nofollow"とした方が理にかなっているのではないでしょうか?例えばログインセッション時のページへのリンクなどはその方がいいように思います。内部リンクrel=nofollowとするのとしないのとで違いはありますか?」
matt:はい、ちょっと前置きが長かったので、ねずみ小僧さんの監修でまず冒頭で結論から。
内部リンクについては、コンテンツをインデックスするのに使う(見つけるのに使う)ので、rel=nofollowがあってもなくても、クロールする際には無視するようにしています。したがって、ご質問のような作業は必要ないです!
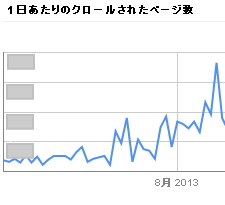
私が大規模なサイト(運用中)のSEOに参画した場合、サイトの現状分析から入るわけですが、まずはGoogleウェブマスターツールを活用します。Googleウェブマスターツールの「HTMLの改善」や「クロールエラー」の項目をチェックし、改善要素があれば早急に対応してもらうよう依頼を出します。
タイトルタグやメタデータの重複があるとPLP(Preferred Landing Page)といって、SERPsに表示されているページと実際にランディングさせたいページが異なってしまうことがあります。
正しく設定してもPLPは発生することがありますが、タグレベルの内部対策が最適化されていれば、それ以外の要因を仮説立てて対策を試みることができます。
今日はHTML改善のワーニングでも出てくるURLの末尾のスラッシュについて検討してみたいと思います。

Google15周年!検索アルゴリズムもオーバーホールにてハミングバード(Hummingbirds)について今後どうなるのか簡単に推測してみましたが、SEJでも今回の改変について「3 Ways Content Will Be Affected by Google’s Latest Hummingbird Update」のタイトルでどうなるか?予想した簡単な論文が掲載されていましたので紹介します。ほぼ我々が今まで考察してきたGoogle社の検索がどう発展して行くのか?という観点で似たような論調となっていますので是非一読してみてください。今後の施策の立案、計画をする上で一つの方向として参考になれば幸いです。

ネズミニ号です。
今日はGoogleのSSL対応により検索クエリが取得できなくなることについて、私がどんなことを思ったかをつらつらと書かせていただきます。
背景としましては、Googleがブラウザとサーバー間の通信を暗号化し、今後Googleアナリティクスなどのアクセス解析ツールでオーガニックからのクエリワードが(not provided)となってしまいます。つまり、これまではサイト訪問者がどのような検索ワードを入力してアクセスしてきたのかを知ることができたのですが、今後その検索ワードが分からなくなってしまうということです。
すでにねずみ小僧ブログではほぼ8割~9割ほどが(not provided)となっていますが、私が管理している他サイトでは(not provided)の割合は高まってきているもののまだ取得可能なクエリワードが存在している状況です。
このことからGoogleが導入したからといってその時点から100%暗号化されるというわけではなく、徐々に浸透していくものと考えられます。

今週でGoogleは設立から15周年。創業時のGoogleHouseでお祝いレセプションが行われたそうです。そこで、あのアミット・シガール氏によりアルゴリズムのオーバーホールについて紹介されたとの事。詳細はまだ明らかになっておりませんが、簡単に推測すると、ナレッジグラフやschema.orgなどに代表される構造化データをより的確に活用し、利用者が打ち込む複雑な問い合わせ意図をより精度高く解釈できるようにしたといった内容のようです。
で、どうなると思いますか?QDDやQDFアルゴリズムがより洗練され、SERPs風景が今までとはちょっと変わったものとなるのかもしれませんね。

![]() 今日の質問はインドバンガロールのハメンスさんからです。「GoogleのクローラーはHTMLのミスなどチェックもしくは気にかけているのでしょうか?ちなみに、Google.comもW3Cでチェックしたら23のERRORと4つのWarningが出ているのですが..一応証拠も添付しておきます!」
今日の質問はインドバンガロールのハメンスさんからです。「GoogleのクローラーはHTMLのミスなどチェックもしくは気にかけているのでしょうか?ちなみに、Google.comもW3Cでチェックしたら23のERRORと4つのWarningが出ているのですが..一応証拠も添付しておきます!」

matt:笑)でスルー、はい、HTMLについて、文法に誤りが無く、クリーンなマックアップしてもらうことが大事なのにはいくつか理由があるんですね。例えば、メンテナンスが楽になるし、アップグレードや更新も楽チンになりますよね。その他にもソースを誰かに渡して作業してもらうときなんかもスムーズです。これだけでも正確なHTMLコードを書くことは価値がありますよね♥(まだまだスルー)