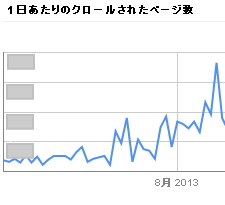
私が大規模なサイト(運用中)のSEOに参画した場合、サイトの現状分析から入るわけですが、まずはGoogleウェブマスターツールを活用します。Googleウェブマスターツールの「HTMLの改善」や「クロールエラー」の項目をチェックし、改善要素があれば早急に対応してもらうよう依頼を出します。
タイトルタグやメタデータの重複があるとPLP(Preferred Landing Page)といって、SERPsに表示されているページと実際にランディングさせたいページが異なってしまうことがあります。
正しく設定してもPLPは発生することがありますが、タグレベルの内部対策が最適化されていれば、それ以外の要因を仮説立てて対策を試みることができます。
今日はHTML改善のワーニングでも出てくるURLの末尾のスラッシュについて検討してみたいと思います。

Google15周年!検索アルゴリズムもオーバーホールにてハミングバード(Hummingbirds)について今後どうなるのか簡単に推測してみましたが、SEJでも今回の改変について「3 Ways Content Will Be Affected by Google’s Latest Hummingbird Update」のタイトルでどうなるか?予想した簡単な論文が掲載されていましたので紹介します。ほぼ我々が今まで考察してきたGoogle社の検索がどう発展して行くのか?という観点で似たような論調となっていますので是非一読してみてください。今後の施策の立案、計画をする上で一つの方向として参考になれば幸いです。

ネズミニ号です。
今日はGoogleのSSL対応により検索クエリが取得できなくなることについて、私がどんなことを思ったかをつらつらと書かせていただきます。
背景としましては、Googleがブラウザとサーバー間の通信を暗号化し、今後Googleアナリティクスなどのアクセス解析ツールでオーガニックからのクエリワードが(not provided)となってしまいます。つまり、これまではサイト訪問者がどのような検索ワードを入力してアクセスしてきたのかを知ることができたのですが、今後その検索ワードが分からなくなってしまうということです。
すでにねずみ小僧ブログではほぼ8割~9割ほどが(not provided)となっていますが、私が管理している他サイトでは(not provided)の割合は高まってきているもののまだ取得可能なクエリワードが存在している状況です。
このことからGoogleが導入したからといってその時点から100%暗号化されるというわけではなく、徐々に浸透していくものと考えられます。

今週でGoogleは設立から15周年。創業時のGoogleHouseでお祝いレセプションが行われたそうです。そこで、あのアミット・シガール氏によりアルゴリズムのオーバーホールについて紹介されたとの事。詳細はまだ明らかになっておりませんが、簡単に推測すると、ナレッジグラフやschema.orgなどに代表される構造化データをより的確に活用し、利用者が打ち込む複雑な問い合わせ意図をより精度高く解釈できるようにしたといった内容のようです。
で、どうなると思いますか?QDDやQDFアルゴリズムがより洗練され、SERPs風景が今までとはちょっと変わったものとなるのかもしれませんね。

![]() 今日の質問はインドバンガロールのハメンスさんからです。「GoogleのクローラーはHTMLのミスなどチェックもしくは気にかけているのでしょうか?ちなみに、Google.comもW3Cでチェックしたら23のERRORと4つのWarningが出ているのですが..一応証拠も添付しておきます!」
今日の質問はインドバンガロールのハメンスさんからです。「GoogleのクローラーはHTMLのミスなどチェックもしくは気にかけているのでしょうか?ちなみに、Google.comもW3Cでチェックしたら23のERRORと4つのWarningが出ているのですが..一応証拠も添付しておきます!」

matt:笑)でスルー、はい、HTMLについて、文法に誤りが無く、クリーンなマックアップしてもらうことが大事なのにはいくつか理由があるんですね。例えば、メンテナンスが楽になるし、アップグレードや更新も楽チンになりますよね。その他にもソースを誰かに渡して作業してもらうときなんかもスムーズです。これだけでも正確なHTMLコードを書くことは価値がありますよね♥(まだまだスルー)

先月ワシントンポスト:Google encrypts data amid backlash against NSA spyingなどでGoogleがサーバー間トラフィック、ブラウザクライアントとサーバー間通信をすべて暗号化すると記事掲載されていました。マット・カッツさんもTweetしていましたが、9月25日ぐらいから非ログイン状態であってもhttpsプロトコルにリダイレクトされるようになったようです。スノーデン氏の暴露からはじまり、米国民の安全とプライバシーの保護という流れを見てみても、この流れは致し方ないと思われます。
さて、ここで困るのが、analytics上で使うLP(ランディングページ)とQW(クエリワード)のクロス分析です。WMTは、Googleがインデックスしてくれたページ(記事)がどういったQWに対し表示が行われ、どれだけクリックスルーされたかを分析できるツール。一方でAnalyticsのトラフィック分析では、直帰率や滞在時間といった参照元referからセッションが続く限り取得できる貴重なデータにより、実際に仕込んだコンテンツがユーザーのQW意図に則しているか否かを判断できる便利なツールでした。しかし、今後このreferを活用した測定が使えなくなる方向になりそうです。本当はGoogle社ではデコード技術をもっているので、やろうと思えばコストはかかりそうですができそうなものですが。。今後の方針・展開に期待したいところです。このような状況ですが、まずはプロだったらという仮定に基づき、きちんと代用手法を見出し、雑草のごとく運用に支障をきたさないためにはどうすればいいか、考えてみました。

約1ヶ月前にピックアップした英会話スクールのサイトが「英会話」というクエリワードでSEO順位、圏外から2ページ目へランクアップしました。前回の記事では、SEO観点からのサイト調査手順及びそこからの改善提案の仮説出しを紹介させていただきました。
実際、「不要なインデックスページの削除」と「SEO会社からの外部リンクを対処したほうが良い」という2つの仮説を挙げましたが、順位回復した今、それらがどのようになっているか経過観測してみることにします。

![]() 今日の質問はミネアポリスのデイジーさんからです。「Eコーマサイトで他社サイトと同じ成分の製品などを販売している場合、リストページなどまったく同じページとなってしまうことがあると思いますが、複製コンテンツとして見なされないために注意すべき点やこうしたらいい!というアドバイスなどありますか?」
今日の質問はミネアポリスのデイジーさんからです。「Eコーマサイトで他社サイトと同じ成分の製品などを販売している場合、リストページなどまったく同じページとなってしまうことがあると思いますが、複製コンテンツとして見なされないために注意すべき点やこうしたらいい!というアドバイスなどありますか?」
matt:オーケーいい質問だね。こういうケースは、こう考えてみましょう。例えば、食品などの成分が記載されたリストとアフィリエイト目的でアマゾンなどからデータを仕入れて作られたリストについて比べてみましょう。
例えば、18ページ近くに上る食品のリストページで材料や成分など食品衛生法やら食品エコ・マイル表示対応等が記載されていてそれらが、食品に関するする表示事項として機能している場合は、あまり問題にはならないでしょう。

本ブログも本格的に始動したのは6月ですが、3ヶ月ほど経ってウェブマスターツール上の検索クエリも徐々に増えつつあります。
ウェブマスターツールの検索クエリでは検索キーワード毎に表示回数、クリック数、CTR、平均掲載順位が表示されます。
クリック数やCTRはある程度の数値を満たさないとクリック数は「10未満」、CTRは「-」で表示されます。
本ブログの「google トレンド 使い方」というクエリワードでは、現在CTRが27%と表示されています。平均掲載順位は3.7位ですので、3~4位くらいに表示されているのでしょう。
みなさんが運用しているサイトの中ではこのCTRが他の検索クエリに対して著しく低い数値のものもあるかと思います。そのような時はT&Dの調整が有効かもしれません。今日はタイトルタグとメタディスクリプション(T&D)の調整に関するお役立ちツールをご紹介します。

コンテンツマーケティングというと人それぞれ思うところがあるとは思います。ネズミ小僧という名を借りて当サイトとで考察している基本概念は、Google社のQDD,QDFというアルゴリズムに注目し、ROIの高いQWに対し、どういったシナリオでパワーをつけて行くか、リスクも加味しながら戦略的に計画を練るという事です。Google社のインデクシングプロセスにおいては、内部・外部リンクグラフからNLP(自然言語処理)を活用した共起語解析による検索QWに関連したフレーズからキャッシュしたページsummaryデータを呼び出すindex(スキーマデータ)等技術・テクニック的にはさまざまなものがあるのも事実ですが、こうした事に悪戦苦闘しても本質的な部分で綿密な設計がなされていないと「(悲劇)Disaster」に見舞われてしまうケースが多いように思います。
今日は、海外でコンサルタントをしている女性のプレゼン記事が当サイトと同じような考え方のもとコンテンツマーケティングを解いていたので紹介します。

先日、キーワードを通じて発想を拡げるツール「reflexa」を紹介しました。
「面白いツールですね!」とのお声をいただきましたので、調子に乗って他のキーワード系ツールをご紹介したいと思います。
今日紹介するのはkizasi.jpラボの「keygram」というツールです。サイト内の開発ブログに詳しい機能説明や利用方法が載っていますので、ぜひ読みながら使ってみてください。
今日は私も最近飲み始めた「青汁」というキーワードで新たなファインディングがあるかやってみました。(アフィリエイト市場も活性化しているジャンルですね)

![]() 今日は、ポーランドからの質問。「こらからIPv6へ移行期となることが予想されますが、GoogleはIPレベルでどう評価するのかテクニカルな情報を教えてください。例えば、IPv4からIPv6移行期にルーターやサーバー側でトンネリング技術やデュアルスタック化により結果的にIPv4とIPv6の2つIPアドレスからを1つのサイトを見ることが出来るケースなど複製コンテンツとしてみなされたりしませんよね?」
今日は、ポーランドからの質問。「こらからIPv6へ移行期となることが予想されますが、GoogleはIPレベルでどう評価するのかテクニカルな情報を教えてください。例えば、IPv4からIPv6移行期にルーターやサーバー側でトンネリング技術やデュアルスタック化により結果的にIPv4とIPv6の2つIPアドレスからを1つのサイトを見ることが出来るケースなど複製コンテンツとしてみなされたりしませんよね?」
matt:ご質問のようなケースは複製コンテンツとして見なしませんのご安心ください。IPv4は、4つのオクテッドからなるアドレスで、これに対しIPv6は6つのオクテッドからなるIPアドレスです。この2つのIPで同じコンテンツを提供しても複製コンテンツとしては見なしませんので心配しないでください。

SEOではホストバリューつまりサイト価値向上を高めるために継続的に施策を行っていきますよね。
同じチーム内では、SEO施策段階として、「コンテンツ種蒔き期」なのか「コンテンツ成熟期」なのか、はたまた「コンテンツ刈取り期」なのか共有をしっかりと図りたいものです。
自分はコンテンツ種蒔き期だと考えて施策しているのに、一緒にいるメンバーは成熟期や刈取り期と考えているとやるべき施策にブレが出てきてしまいます。
私は当初計画を立てた通りにまずはコンテンツを投入し尽すことが大切と考えていますが、ある程度コンテンツを投入してアクセスを引っ張ってくるページが出てくると、その芽を摘もうと何やらチューニングしたくてしょうがないという人たちが現れるものです。
チューニングすることでもっとアクセスが増えるとお考えなのでしょうね。その考えも一理ありますので、今日はねずみ流チューニング方法の中から一つご紹介します。

![]() 今日は、インドのナンディタさんからの質問。「パンダアップデートは通常のインデクシングプロセスに組み込まれてしまいましたが、パンダにヒットしてしまったとかパンダから回復したとかどうやって判断すればいいですか?いい方法がありましたら教えてください!」
今日は、インドのナンディタさんからの質問。「パンダアップデートは通常のインデクシングプロセスに組み込まれてしまいましたが、パンダにヒットしてしまったとかパンダから回復したとかどうやって判断すればいいですか?いい方法がありましたら教えてください!」
matt:はい、そうですねぇ。パンダは、通常プロセスに組み込まれてしまったので、「既にヒットしていた場合、回復したかをどうやって知ればいいか?」..ということですね。昔のようにパンダやるぞぉーとはもう言わないですからねぇ。

約1ヶ月前、イケダハヤト氏によるRettyのSEOに関する記事を読んで、ねずみ小僧なりの考えを述べさせていただきました。(→前回の記事はこちら)1ヶ月ほど経過してRettyの各ワードに変化があったのか、なかったのか経過観測をしてみたいと思います。どうなっているか楽しみですね。
8月10日時点で1位であった「新宿 カフェ」「渋谷 カフェ」「池袋 カフェ」「渋谷 ラーメン」「渋谷 パンケーキ」。これらのクエリワードは9月12日時点でも安定して1位を獲得しております(パチパチ)。
そのほかのキーワード群も見てみましょう。

イギリスのZazzle社よりSocialMediaに関するマネタイズ可能なオンラインマーケティングについての考え方が記されたホワイトペーパーがレポートされていましのたで紹介します。簡単な内容は、こんな感じ:「今までソーシャルメディアというと経営者にとってはブランドバリューとかエンゲージメントとか言うが、お金を生まないTOY(おもちゃ)みたいなものだった。」そして、「お金を生む顧客を探す領域はGoogleのフィールドだ。」という考え方が主流であった。しかし、これからは、Socialに関しても、きちんと数学・アルゴリズム視点で科学されることで、マネタイズ可能なビジネスラインに乗ってくるはずだ。興味深い内容ですので、是非時間に余裕のある方は読んでみてください。

![]() 今日は、イギリスのトビーさんからの質問です。「SEOのためではなく、トラフィックを誘導するためにリンクビルディングを行っています。こうしたリンクにちゃんとnofollowをつけておけば、ペナルティの心配はないということでよろしいですか?つまり、nofollowリンクはサイトのランキングには影響はないという理解でよろしいですか?」
今日は、イギリスのトビーさんからの質問です。「SEOのためではなく、トラフィックを誘導するためにリンクビルディングを行っています。こうしたリンクにちゃんとnofollowをつけておけば、ペナルティの心配はないということでよろしいですか?つまり、nofollowリンクはサイトのランキングには影響はないという理解でよろしいですか?」
matt:はい。nofollowリンクは、サイトランクには影響しません。端的に答えると「YES」です。心配しないでください。ただ、折角のマット・カッツコーナーですので、ちょっと特殊な例も説明しておきましょう。
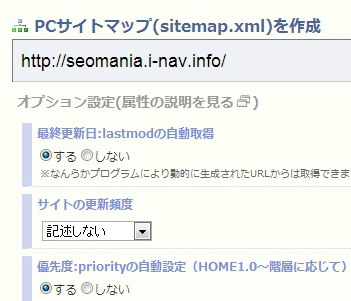
ウェブで簡単にXMLサイトマップを作成できるツール「sitemap.xml Editor」をご紹介します。そもそもサイトマップとは、サイト訪問者がサイト内で目的のページを見つけるのに困ったときに閲覧することがある道標的な役割を持つページです。一方XMLサイトマップは検索エンジンがサイト内のページを見つけるのに役立つファイルのことです。
「Google検索エンジン最適化スターターガイド」では、サイトマップについて下記のようにポイントを解説しています。確認のために再度おさらいしておきましょう。
HTMLのサイトマップをサイトに置き、XMLサイトマップも使おう
サイトのすべてのページ、もしくは(何百、何千ものページがあるサイトの場合は)主要なページへのリンクが張られたHTMLのサイトマップ(sitemap《先頭が小文字》)があると、ユーザーにとって便利です。また、XMLサイトマップSitemap《先頭が大文字》)を活用すると、検索エンジンがサイト内にあるすべてのページを発見する手助けになります。
- HTMLサイトマップはリンク切れなどを確認し、常に最新の状態を保つ
- HTMLサイトマップを作るときは、ただリンクを羅列するのではなくテーマごとにまとめるなど、整理して並べる
改めて読まれていかがでしょうか?
自サイトでしっかり対応できているか確認してみるのもいいかもしれませんね。ここでは簡単にサイトマップの作成方法とチェック観点についてご説明します。
昨年一つのプロジェクトとしてオーガニック対策に関わった際に2号さんとともに練った戦略と、実際に6ヶ月ぐらいで圏外サイトをターゲットとするBIGワードで1ページまでもっていた際の戦術についてそのエッセンスを一部公開させていただきます。あくまでも一つの事例ですが、当サイトでの考え方がたまたまはまった一つのケーススタディとして参考となれば幸いです。メモ書きのような荒い原稿となりまして恐縮ですが、おそらく2号さんがきちんと整理して体系立てて、将来可能な範囲でディスクローズしていただけることを楽しみにしています。

今日は、ちょっとSEOから離れて、Android端末で実装されている音声検索について映像とともに今後のGoogle社の将来を垣間見てみようと思います。さながらキューブリックの「2001年宇宙の旅」のハルのように対話形式による自然な操作が実現できているような音声検索映像です。注目すべき点としては、映像の中で紹介されている機能は現時点ですでにUS版Andorid端末GoogleAppで実現できているということです。残念なことに、日本語ですと、電卓を出したり、東京の人口といったことは機能しましたが一部ではまだ検索結果を表示するに留まっています。このUS版Androidに実装されている音声検索の機能を見る事で、数年先にGoogle社がやろうとしていることが垣間見れるヒントになるかもしれません。

株式会社Preferred Infrastructureが提供している連想検索エンジン「reflexa」をご紹介します。
サイトを運用し始めてしまうとなかなか利用する機会がないのですが、新規案件などで特定の分野でサイトを立ち上げようかと思案している場合などに発想を広げるといった意味合いで利用価値が高いツールと考えています。
実際にクエリワードを入れてどのような調査ができるのか、またどのような結果が出るのかを見てみることにしましょう。
最近流行の「医療保険」というクエリワードで入力してみました。

Comparing Rank-Tracking Methods: Browser vs. Crawler vs. Webmaster Toolsという記事で統計的にQWの順位計測方法により、どういう相関があるか面白いレポートがありましたので紹介します。検定手法は下記の通り以下の4つの手法でMoz.comに関する500ほどのQWを検討。このQWはある程度の順位と、実クリックデータを有するものをピックアップしたそうです。
- Browser – Personalized(ログイン状態での検索)
- Browser – Incognito(ChromeのIngognitoモード、履歴も一切記録しないステレスモード)
- Crawler(mozで開発した?スパイダーみたいなクローラーでSERPsをクロールして結果をキャッシュ)
- Google Webmaster Tools (GWT)
さて、結果はいかに。

![]() 今日の質問は、オランダのウォルターさんからだ!「refererなどから自動で検索ワードを拾って関連するページを自動で生成するような行為に対してGoogleはどうリアクションするのでしょうか?例えば”カフェインを取ることのリスク”という検索ワードに対応して、”カフェイン摂取に関する記事は存在しません”代わりに沢山の広告が表示されているようなケースなどです。」
今日の質問は、オランダのウォルターさんからだ!「refererなどから自動で検索ワードを拾って関連するページを自動で生成するような行為に対してGoogleはどうリアクションするのでしょうか?例えば”カフェインを取ることのリスク”という検索ワードに対応して、”カフェイン摂取に関する記事は存在しません”代わりに沢山の広告が表示されているようなケースなどです。」
matt:はいはい。これは言うまでもなく、バッドエクスペリエンスなケースです。(レイターならirellevantもしくはoff topic or spam like conductとしてRatingされるでしょう)。ウェブマスターガイドラインにもきちんと公開しています。「自動生成ページでなんの価値もないページはスパムとみなしますよ」と。

ウェブマスターツールの手動対策ビューアでサイトリンク「部分一致」のウェブスパム対策が課されていたサイトに対して、スパム解除された事例を共有させていただきます。
このドメインは、以前Googleより不自然なリンクのアラートが届いていましたが、主要ワードで順位下落したもののアクセス数に大きな変化がなかったとのことで、新たな恣意的なリンク施策は行わずにサイト運用を継続していました。
今回、Googleの「手動対策ビューアの導入」で改めてスパム対策が課されているのが明示的に記述されたのを受け、何か対策を取らねばということで相談がありました。

devo社が提供している「aramakijake.jp」の使い方をご紹介します。このツールを利用することで、クエリワードの月間推定検索数とSEO順位ごとの推定アクセス数がGoogleとYahoo!とに分けて予測してくれるツールです。
まずは仮説をベースにSEOによる収益シミュレーションや投資コスト、想定売上を算出し、ロジカルに運営していく必要があります。
SEOはブラックボックスな部分が往々にしてありますが、インハウスSEOとしてSEO業務に当たっている場合、SEO担当者が分からなければ、会社内にいる他の誰も分かりませんので、自信を持って計画を立てていくようにしましょう。
もちろん、あくまでも推定の数ですので、この通り行くかどうかは保証できません。事前のプランニングにおいて「このツール上で」という条件を入れつつ、実データが収集出来次第、調整を図っていくという運用が良いと考えます。